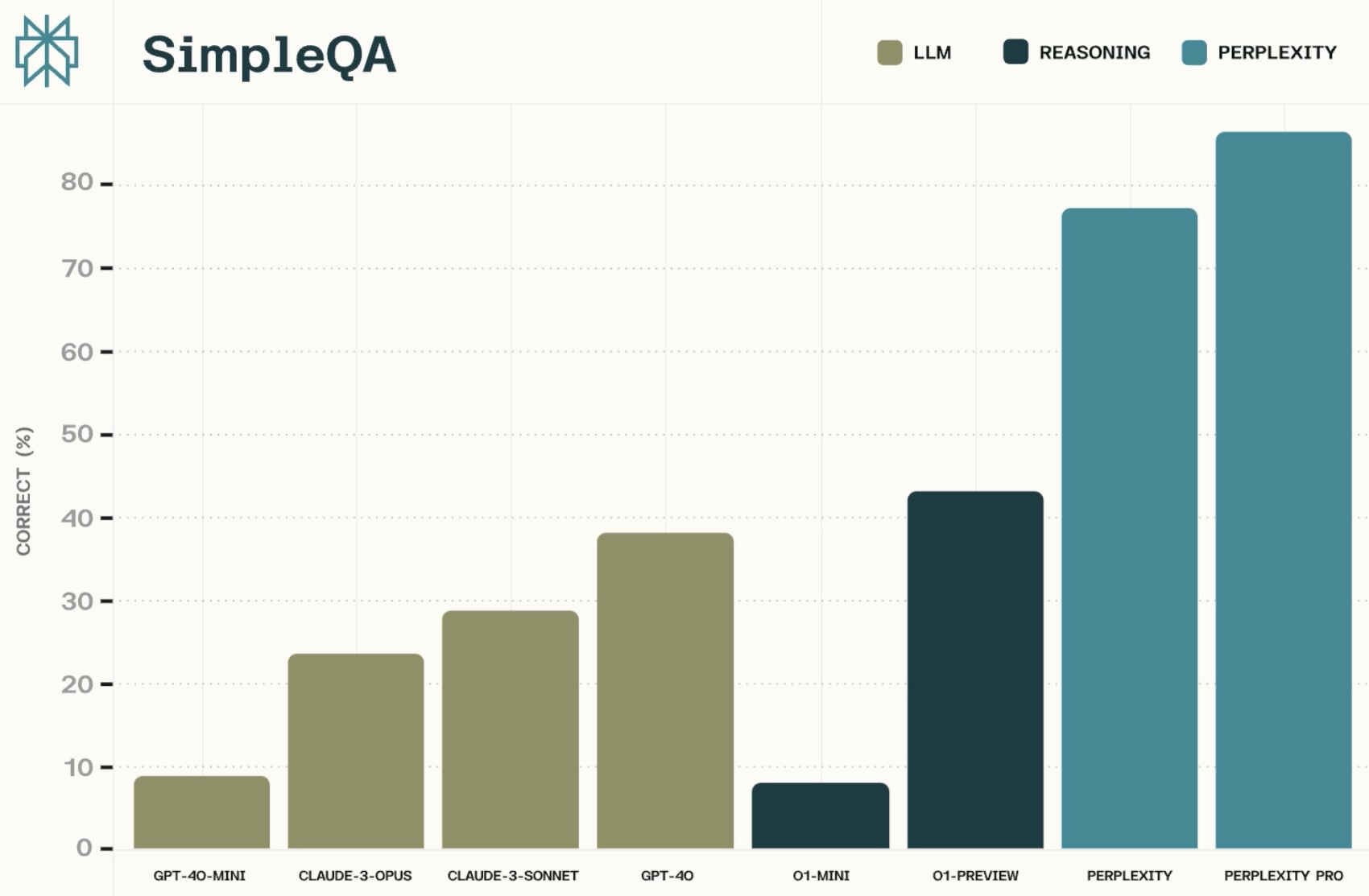
Perplexity AI, a company focused on creating more informative and comprehensive search results, has achieved a significant milestone. Its models have outperformed other leading AI models in a recent benchmark focused on factuality.
OpenAI recently released an important new benchmark, SimpleQA, which evaluates whether models can answer short, fact-seeking questions using only the information they are trained on. This new benchmark is intended to push frontier models today and continue to advance the field forward as next generation models are developed.
The resulting evaluations are challenging for frontier models that don’t have access to real time data. However, both default Perplexity and Perplexity Pro significantly outperforms models on this benchmark, indicating the power of combining LLMs with web-search rather than just relying on the models alone.
This achievement underscores Perplexity’s commitment to providing accurate and reliable information. By combining the power of large language models with advanced web search capabilities, Perplexity’s models are able to deliver more factual and informative responses to user queries.
The company’s approach involves carefully selecting and incorporating relevant information from the web to augment the capabilities of its language models. This hybrid approach ensures that the generated responses are not only well-written but also grounded in real-world facts.
This breakthrough in factuality has the potential to revolutionize the way we search for and consume information online. As AI continues to evolve, Perplexity’s commitment to accuracy and reliability sets a new standard for the industry.
Leave a Reply